
Time To Recognize Authorship of Open Data

At times, it seems there’s an unstoppable momentum towards the principle that data sets should be made widely available for research purposes (also called open data). Research funders all over the world are endorsing the open data-management standards known as the FAIR principles (which ensure data are findable, accessible, interoperable and reusable). Journals are increasingly asking authors to make the underlying data behind papers accessible to their peers. Data sets are accompanied by a digital object identifier (DOI) so they can be easily found. And this citability helps researchers to get credit for the data they generate.
But reality sometimes tells a different story. The world’s systems for evaluating science do not (yet) value openly shared data in the same way that they value outputs such as journal articles or books. Funders and research leaders who design these systems accept that there are many kinds of scientific output, but many reject the idea that there is a hierarchy among them.
In practice, those in powerful positions in science tend not to regard open data sets in the same way as publications when it comes to making hiring and promotion decisions or awarding memberships to important committees, or in national evaluation systems. The open-data revolution will stall unless this changes.
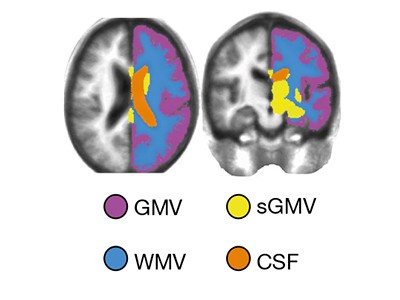
Read the paper: Brain charts for the human lifespan
This week, Richard Bethlehem at the University of Cambridge, UK, and Jakob Seidlitz at the University of Pennsylvania in Philadelphia and their colleagues publish research describing brain development ‘charts’ (R. A. I. Bethlehem et al. Nature https://doi.org/10.1038/s41586-022-04554-y; 2022). These are analogous to the charts that record height and weight over the course of a person’s life, which researchers and clinicians can access.
This work has never been done on such a scale: typically in neuroscience, studies are based on relatively small data sets. To create a more globally representative sample, the researchers aggregated some 120,000 magnetic resonance imaging scans from more than 100 studies. Not all the data sets were originally available for the researchers to use. In some cases, for example, formal data-access agreements constrained how data could be shared.
Some of the scientists whose data were originally proprietary became active co-authors on the paper. By contrast, researchers whose data were accessible from the start are credited in the paper’s citations and acknowledgements, as is the convention in publishing.
Such a practice is neither new nor confined to a specific field. But the result tends to be the same: that authors of openly shared data sets are at risk of not being given credit in a way that counts towards promotion or tenure, whereas those who are named as authors on the publication are more likely to reap benefits that advance their careers.
Credit data generators for data reuse
Such a situation is understandable as long as authorship on a publication is the main way of getting credit for a scientific contribution. But if open data were formally recognized in the same way as research articles in evaluation, hiring and promotion processes, research groups would lose at least one incentive for keeping their data sets closed.
Universities, research groups, funding agencies and publishers should, together, start to consider how they could better recognize open data in their evaluation systems. They need to ask: how can those who have gone the extra mile on open data be credited appropriately?
There will always be instances in which researchers cannot be given access to human data. Data from infants, for example, are highly sensitive and need to pass stringent privacy and other tests. Moreover, making data sets accessible takes time and funding that researchers don’t always have. And researchers in low- and middle-income countries have concerns that their data could be used by researchers or businesses in high-income countries in ways that they have not consented to.
But crediting all those who contribute their knowledge to a research output is a cornerstone of science. The prevailing convention — whereby those who make their data open for researchers to use make do with acknowledgement and a citation — needs a rethink. As long as authorship on a paper is significantly more valued than data generation, this will disincentivize making data sets open. The sooner we change this, the better.