

A review of Wade, N.C. (2014). A Troublesome Inheritance. Penguin, 288 pages. Google Books page.
In his new book A Troublesome Inheritance, Nicholas Wade argues that many of the differences between people from different places that we typically attribute to culture are, in fact, due to genetics. These include major social and economic disparities—whether nations are democratic or autocratic, warlike or peaceable, prosperous or poor. Wade argues that these differences arise from different evolutionary histories experienced by people of different races, and backs his claims with extensive citation of modern genetic data.
Many readers are likely to find Wade’s arguments convincing, and many reviewers already have. However, reading A Troublesome Inheritance as a population geneticist, I repeatedly found that Wade misunderstands or misrepresents the original scientific work that he cites.
I am far from the first geneticist or evolutionary biologist to take issue with Wade’s claims. Biological anthropologist Jennifer Raff has published a withering critique of Wade’s population genetics argument, which covers much of what I will discuss here. I highly recommend reading her article, because while I am familiar with the kinds of genetic data and analyses discussed in A Troublesome Inheritance, Raff is an expert on their specific application to humans. I also recommend Allen Orr’s review for The New York Review of Books as the most comprehensive treatment by an evolutionary biologist, and Eric Michael Johnson’s dissection of Wade’s adaptationist claims. Here, I will focus on the book’s fifth chapter, “The Genetics of Race,” where Wade argues that patterns of genetic structure in human populations “naturally” sort into racial groupings. Wade’s thesis that social, cultural, and economic differences are the product of substantially different evolutionary histories requires biologically meaningful genetic differences between his racial groupings in the first place—and digging into the human population genetics data reveals that those differences are more ephemeral than he thinks.
Clustering doesn’t find (only) five races
First and foremost, Wade claims that when population geneticists apply a class of statistical methods called clustering algorithms to datasets containing hundreds or thousands of genetic markers, they objectively identify five geographic groups that he calls “continental races”—differentiating African, European/Middle Eastern/South Asian, East Asian, Oceanian, and American people. What he does not make particularly clear is that while clustering methods do group genetic samples without direct instructions, the algorithms do not decide how many clusters there are. The geneticists using them do.
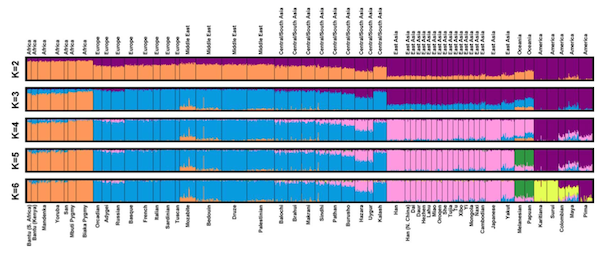
Clustering genetic data from 1,024 human samples. Figure 2 from Rosenberg et al. (2005)
A 2005 study by Noah Rosenberg and colleagues, which Wade treats as the last word on the existence of racial genetic clusters, used a program called STRUCTURE to identify clusters in a worldwide gentic dataset. STRUCTURE’s results are visuzalized as a row of bars, one for each individual, colored proportionally to their probability of assignment to each cluster. From the figure above (their Figure 2) you can see that Rosenberg et al actually used STRUCTURE to split their data into 2, 3, 4, 5, and 6 groups. It’s true that, when K, the number of groups, was set to 5, the 5 clusters more or less correspond to Wade’s “continental races.” But in fact, when the authors compared the number of individuals in their dataset who were ambiguously assigned at each value of K, they found the result was slightly more “clustered” with K=6, which splits the American samples.
Jennifer Raff has a good deal of fun with the fact that Wade sort of acknowledges this arbitrariness, then hand-waves it away by saying that “the five-race, continent-based scheme seems the most practical for most purposes.” As Raff notes, throughout the rest of the book, the scale and number of racial divisions turns out to be whatever Wade wants them to be in the context of making a particular point.
Another limitation of STRUCTURE is that it cannot find clusters that are not sampled. The dataset analyzed by Rosenberg et al. misses a lot of diversity within one of Wade’s “continental races,” Africa. As the ancestral home of modern humans, Africa contains more genetic diversity than any other continent, but many worldwide human datasets sample fewer African individuals than Europeans.
A 2009 study by Sarah Tishkoff and colleagues added more than 2,000 individuals from Africa to the data analyzed by Rosenberg et al. The authors ran STRUCTURE on this new global dataset, evaluating the “fit” of a range of K values—and they found that the data best supported not five population clusters but 14. In other words, if we were to split humanity into “objective” races using genetic clustering, we’d end up with a lot more than five races, and at least half would be within Africa.
Wade discusses this paper at length, but misses that point entirely. In introducing Tishkoff’s results, Wade implicitly compares differentiation within Africa to the differentiation between European populations. But the variation within Europe is not on the same scale as variation within Africa.
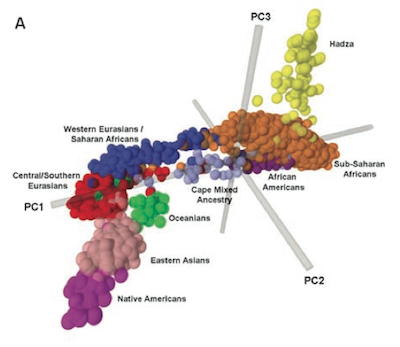
A principal components plot of genetic variation in the dataset of Tishkoff et al. (2009)
The above figure is a panel from Figure 2 of Tishkoff et al. (2009), plotting individual genetic samples so that the distance between points represents genetic differences between samples. Europeans are within that cluster of blue points, lumped with the Middle East and North Africa. Compare that blue blob to the space occupied by the orange, yellow, purple, and lavendar points representing individuals from Sub-Saharan Africa, Hadza, African American, and South Africans of mixed ancestry.
It’s clustered! It’s a cline! It’s a clustered cline!
Wade frames the Rosenberg et al. (2005) results as the winning volley in a debate over whether human diversity falls into discrete clusters, or is continuously distributed across space—in what population geneticists call clines. But he misses a key limitation of the STRUCTURE analysis, which is that given a set of genetic samples from a clinally distributed population, the algorithm is perfectly capable of identifying clusters from them.
This is because of isolation-by-distance, a fundamental process of population genetics. Populations separated by sufficient geographic distance will be genetically different even if they are connected by migrants and interbreeding. Before the advent of planes, trains, and automobiles, a genetic variant that first appeared in France could, eventually, make its way to China because there were human populations all the way between those two points—but because that could take many generations, we’d expect that variant to be more common in France than China.
In a 2012 paper (which I discussed on this very blog), Patrick Meirmans pointed out that this pattern of clinal genetic variation is enough create apparent differentiation in a dataset. Meirmans simulated an array of populations separated by space and linked by migration, and found that dividing those populations at the mid-point of the simulated cline produced groupings with an average of 3.7%, and up to 7.6%, genetic differentiation.
That’s more than enough differentiation for STRUCTURE to find clusters in a cline, and Rosenberg et al. were well aware of this issue. They quote an earlier paper in which they had identified ambiguosly clustered individuals in an smaller sample:
In several populations, individuals had partial membership in multiple clusters, with similar membership coefficients for most individuals. These populations might reflect continuous gradations across regions or admixture of neighboring groups
Indeed, Rosenberg et al. found a strong correlation between genetic variation and geography—geographic distance between populations explained 69% of the variation in genetic differentiation in their data. When they also accounted for major barriers like oceans and mountain ranges, geography explained 72.9% of the variation. On average, a major barrier increased genetic differentiation between populations by 1.5%, and Rosenberg et al. concluded that this tiny fraction of variation is what allowed STRUCTURE to find clusters in their data:
… the discontinuities that give rise to genetic clusters—as we have stated previously—constitute a relatively small fraction of human genetic variation.
How much differentiation are we talking about?
What matters for Wade’s case is not just that STRUCTURE finds clusters in human genetic data, but how much genetic variation differentiates those clusters. Rosenberg et al. found that the actual proportion of variation generating their clustering result is quite small; but without accounting for the effects of geography it is possible to ask what proportion of variation differentiates populations or other groupings.
To begin his discussion of this point, Wade cites Richard Lewontin’s 1972 estimate that about 15% of variation is either between broad racial groups (6.3%) or populations within those racial groups (8.3%). Lewontin aruged that this meant differentiation between racial groups was not particularly significant. Wade refutes Lewontin by noting that none other than Sewall Wright, the inventor of the FST metric of genetic differentiation, identified 15% as “moderate genetic differentiation,” and, in his 1978 treatise Evolution and the Genetics of Populations, said that the differences between human racial groups would be sufficient to identify them as subspecies, if they were seen in non-human organisms.
Analyses based on more modern data find that worldwide, the largest differentiation between human populations tends to be on the order of 10%. Those still fall within Wright’s “moderate genetic differentiation,” but they are estimates of the proportions of total human population genetic diversity, not absolute differences in DNA sequences. It is quite possible to have 10% differentiation that without much biological meaning, if humans are not a very genetically diverse population.
It turns out that this is exactly the case, which we can see by comparing variation within humans to variation within closely related species. In a 2013 paper, Javier Prado-Martinez and a large consortium of collaborators (including Sarah Tishkoff) made that comparison using genome-wide DNA sequence data from humans and three species of great apes. Their samples from chimpanzees, gorillas, and orangutans each had two to three times as much DNA sequence variation as a human sample from multiple continents. In fact, the worldwide human sample had less variation than three subspecies of chimpanzees.
Population structure, therefore selection?
Wade devotes much of the rest of his chapter on “The Genetics of Race” to arguing that the genetic differences we see among human populations, subtle as they are, may be substantially due to natural selection. He cites some familiar cases where selection on individual human genes varies with geography—including lactose tolerance in Europe and Africa, and hemoglobin adaptation for high altitude in Tibet.
What Wade is particularly interested in, though, are soft selective sweeps, cases in which a trait is influenced by many different sites in the genome, so that small changes in the frequency of variants at each site can add up to big changes in a population’s average value for that trait. Wade correctly notes that soft sweeps can respond to environmental changes much more rapidly than “hard” selective sweeps by a single variant with a large effect, because mutations of large effect are rare and unlikely to be present in a population prior to environmental change that might make them useful. So, he concludes, if racial groups differ in social and economic factors, any underlying genetic differences may nevertheless be quite subtle.
This is very close to arguing that Wade need not provide direct evidence of genetic differences between races that create social and economic differences at all. As he notes, the subtle genetic effects of soft sweeps are particularly difficult to isolate from the effects of isolation by distance—in the absence of evidence, Wade is saying that genetic differences in social and economic factors could be out there, somewhere.
In fact, recent genome-scale work has been able to isolate subtle signatures of what may be soft selective sweeps in human genetic data. Jeremy Berg and Graham Coop devised a means to test for subtle population genetic differentiation at loci with previously documented associations to height, skin pigmentation, body mass index, type 2 diabetes risk, and inflammatory bowel diseases. They found patterns that may be consistent with geographically varying selection acting on height, skin pigmentation, BMI, and type 2 diabetes—but most of these emerged on spatial scales smaller than Wade’s continental races.
What’s more, Berg and Coop examined traits with well known, well studied genetic bases; we knew long before their work that height and skin pigmentation vary between populations, and that they are heritable. There is no comparable baseline of data for social and behavioral traits. The most recent, rigorous study of a such a trait—how many years of education people complete, a numerical proxy for cognitive and social performance—found that only a miniscule proportion of variation was explainable by specific genetic markers. Its authors argued that their results call into question a lot of prior work with much less powerful datasets, which can be misled by exactly the kind of subtle population genetic differences we see in humans.
A STRUCTURE plot is not a Rorschach test
So with all due respct to Sewall Wright, modern genetic data pretty clearly show that if aliens arrived tomorrow and started sequencing the DNA of planet Earth, they would probably not sort Homo sapiens into multiple genetic subspecies. It is true that people from different geographic locations look different—and we have known that these visible differences have a genetic basis since the first time distant tribes met and interbred. But that interbreeding, and our drive to explore and settle the world, have maintained genetic ties among human populations all the way back to the origin of our species.
As the evolutionary anthropologist Holly Dunsworth notes in her discussion of A Troublesome Inheritance, whether you choose to focus on the visible differences among human populations, or on those deep and ancient genetic ties, comes largely down to a matter of personal inclination. Knowing what I do of evolutionary genetics, and of how our judgments about the visible differences among human populations have shifted over time, I’m far more inclined to think that the social, economic, and cultural differences among human societies are products not of our genes, but of how we treat each other.
Wade’s inclinations are, quite obviously, different from mine. However, comparing Wade’s claims to the scientific work he cites, I find it hard to conclude that we are simply looking at the same data with different perspectives. Time and again, data that refutes his arguments is not only available and widely cited in the population genetics literature—it is often in the text of the papers listed in his endnotes.
References
Clark A.G., Nielsen R., Signorovitch J., Matise T.C., Glanowski S., Heil J., Winn-Deen E.S., Holden A.L. & Lai E. (2003). Linkage disequilibrium and inference of ancestral recombination in 538 single-nucleotide polymorphism clusters across the human genome., American Journal of Human Genetics, DOI: 10.1086/377138
Harpending H. & Rogers A. (2000). Genetic perspectives on human origins and differentiation., Annual Review of Genomics and Human Genetics, DOI: 10.1146/annurev.genom.1.1.361
Lewontin R.C. (1972). The apportionment of human diversity, Evolutionary Biology, 381-398. DOI: 10.1007/978-1-4684-9063-3_14
Meirmans P.G. (2012). The trouble with isolation by distance., Molecular Ecology, DOI: 10.1111/j.1365-294X.2012.05578.x
Prado-Martinez J., Sudmant P.H., Kidd J.M., Li H., Kelley J.L., Lorente-Galdos B., Veeramah K.R., Woerner A.E., O’Connor T.D. & Santpere G. & (2013). Great ape genetic diversity and population history., Nature, DOI: 10.1038/nature12228
Rietveld C.A., Medland S.E., Derringer J., Yang J., Esko T., Martin N.W., Westra H.J., Shakhbazov K., Abdellaoui A. & Agrawal A. & (2013). GWAS of 126,559 individuals identifies genetic variants associated with educational attainment., Science, DOI: 10.1126/science.1235488
Rosenberg N.A., Pritchard J.K., Weber J.L., Cann H.M., Kidd K.K., Zhivotovsky L.A. & Feldman M.W. Genetic structure of human populations., Science, DOI: 10.1126/science.1078311
Rosenberg N.A., Mahajan S., Ramachandran S., Zhao C., Pritchard J.K. & Feldman M.W. (2005). Clines, clusters, and the effect of study design on the inference of human population structure., PLoS Genetics, DOI: 10.1371/journal.pgen.0010070
Tishkoff S.A., Reed F.A., Friedlaender F.R., Ehret C., Ranciaro A., Froment A., Hirbo J.B., Awomoyi A.A., Bodo J.M. & Doumbo O. & (2009). The genetic structure and history of Africans and African Americans., Science, DOI: 10.1126/science.1172257
Wang C., Zöllner S. & Rosenberg N.A. (2012). A quantitative comparison of the similarity between genes and geography in worldwide human populations., PLoS Genetics, DOI: 10.1371/journal.pgen.1002886
Jeremy Yoder is a postdoctoral associate in the Department of Plant Biology at the University of Minnesota. He also blogs at Denim and Tweed and Nothing in Biology Makes Sense!, and tweets under the handle @jbyoder.
Spread the word